Overview
Deep Learning Hard (DL-HARD) is a new annotated dataset building upon standard deep learning benchmark evaluation datasets. It builds on TREC Deep Learning (DL) questions extensively annotated with query intent categories, answer types, wikified entities, topic categories, and result type metadata from a leading web search engine.
Based on this data, we introduce a framework for identifying challenging questions. DL-HARD contains 50 queries from the official 2019/2020 evaluation benchmark, half of which are newly and independently assessed. We perform experiments using the official submitted runs to DL on DL-HARD and find substantial differences in metrics and the ranking of participating systems.
Overall, DL-HARD is a new resource that promotes research on neural ranking methods by focusing on challenging and complex queries.
Annotations & Entity Links
Annotations are provided for 400 queries from the DL 2019/20 test datasets (link). The annotations tsv has the following columns:
- 0: Topic id
- 1: Query
- 2: Query Intent: Recently developed question intent taxonomy developed for web questions [Cambazoglu et al., 2021].
- 3: Answer Type: Manual annotation of target answer type for web questions.
- 4: Topic Domain: Breakdown of questions by topic domain.
- 5: SERP Result Type: Answer type provided by the Search Engine Results Page (SERP). HTML of queries found: here.
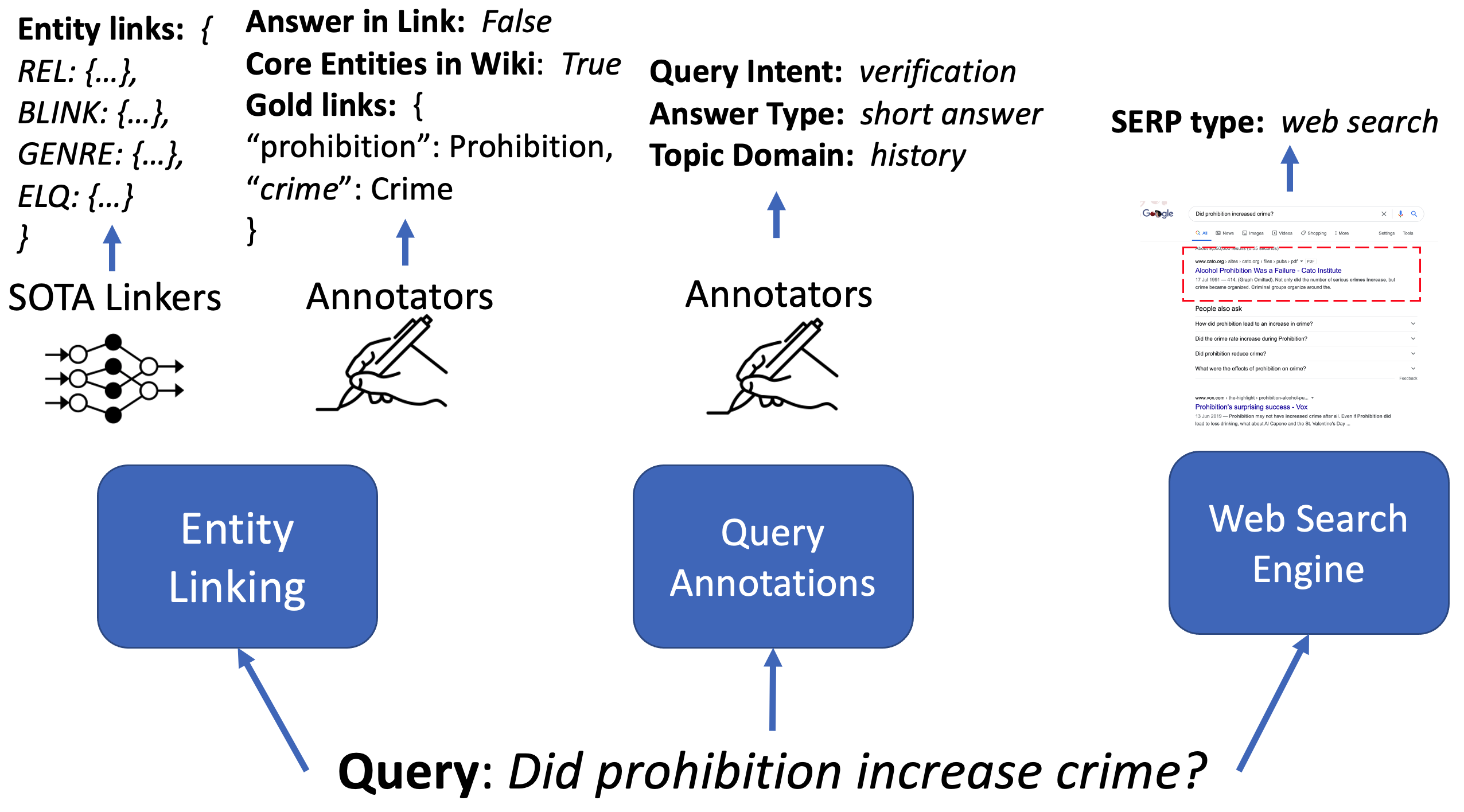
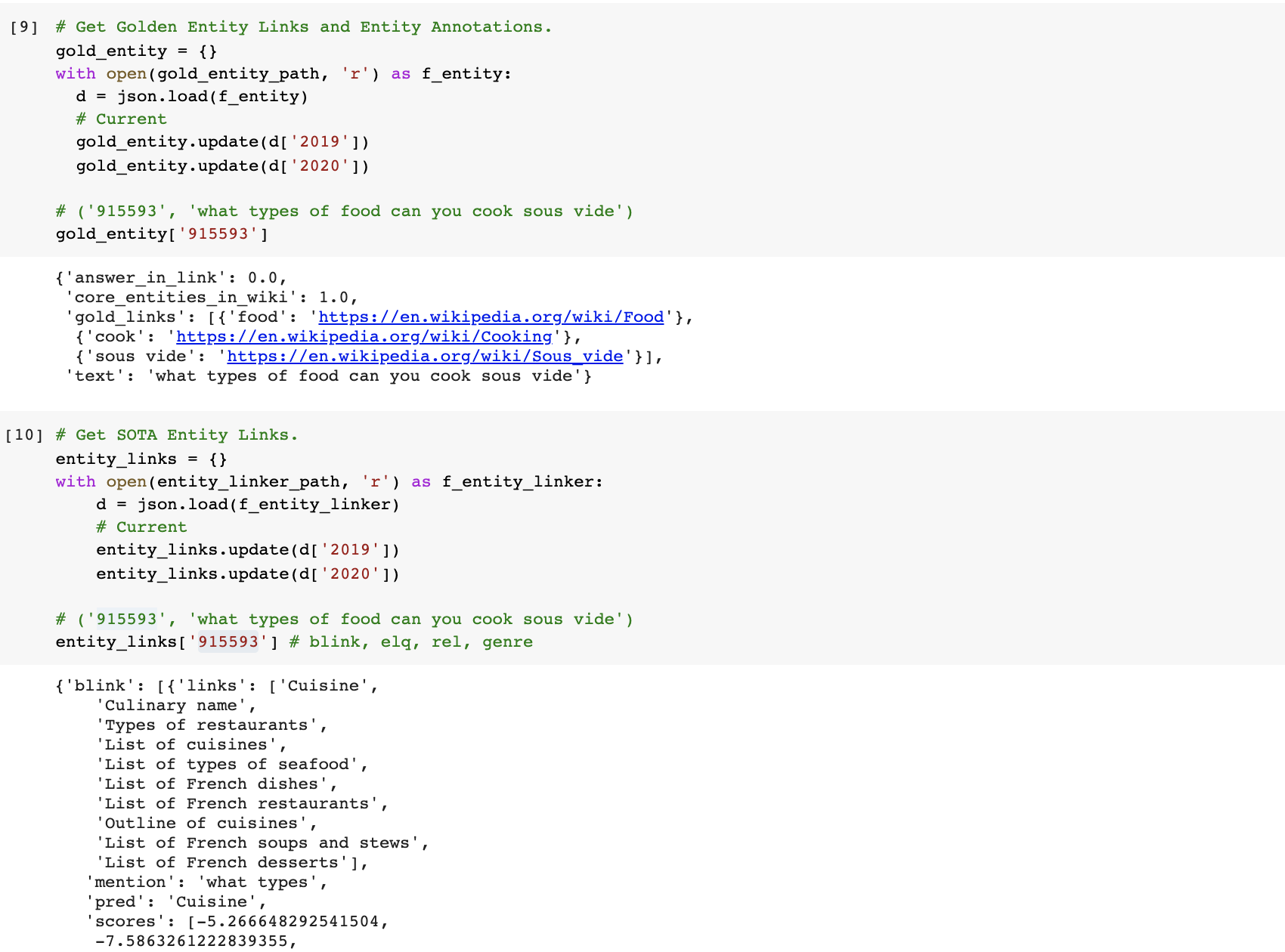
High-recall results for SOTA entity linkers (REL [Van Hulst et al., 2020], BLINK [Wu et al., 2020], GENRE [De Cao et al., 2020], ELQ [Li et al., 2020]) are provided for all 400 queries from the DL 2019/20 test datasets. Golden entity links to Wikipedia (2021/02/27) are also provided: here. These include annotations: (1) Answer in Link: whether question is answered within linked Wikipedia page, and (2) Core Entities in Wiki: whether any core entities of the question were not found in Wikipedia.
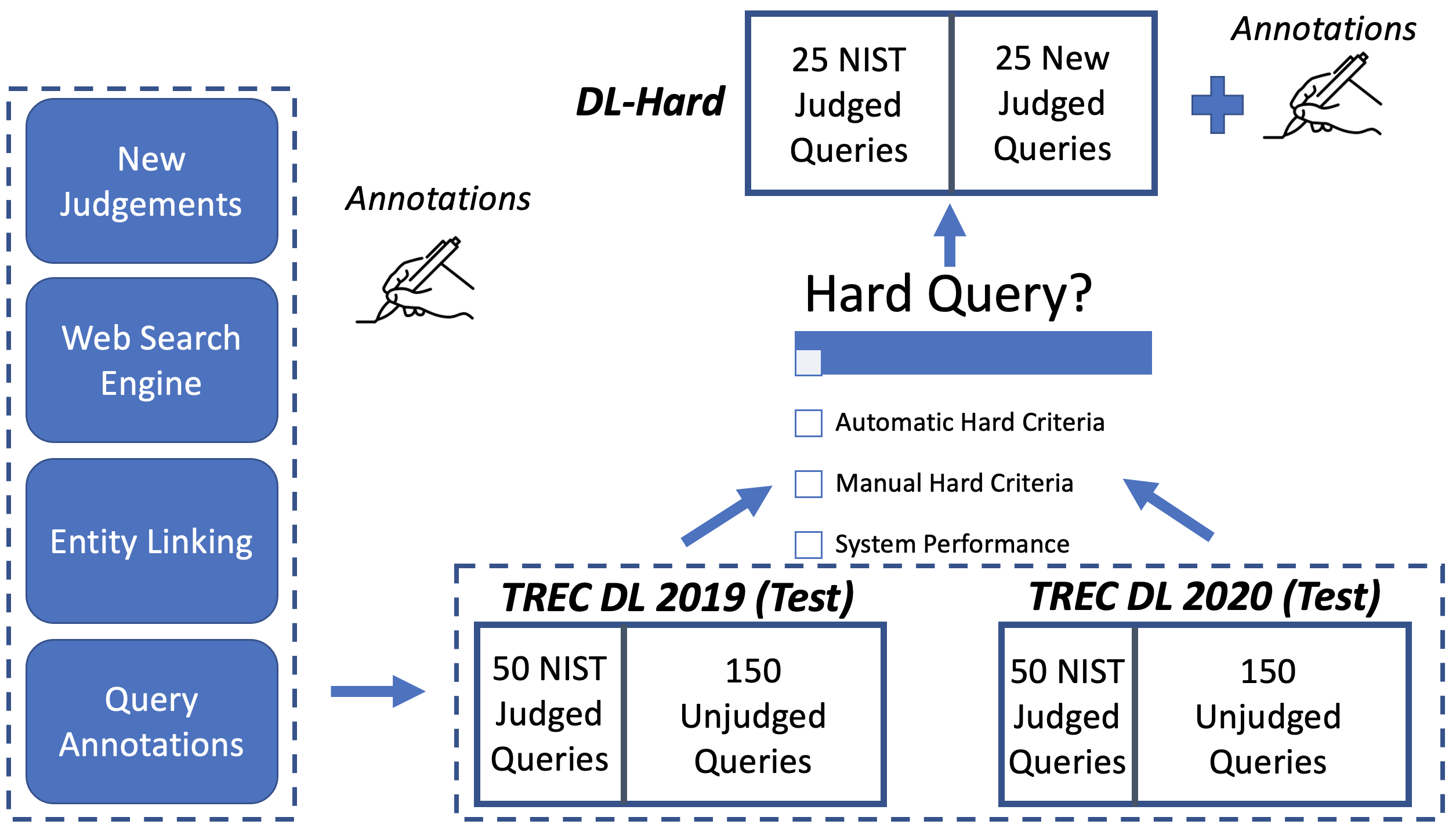
Hard Queries
To differentiate system performance between large neural ranking models new challenging and complex benchmark queries are required. Hard queries were identified within the DL 2019/20 testsets through:
Automatic Hard Criteria: Because manually reviewing all candidate queries is time consuming, we explore the use of annotated metadata only, without requiring knowledge of system effectiveness. Google’s web search answer type as a base with additional List and Reason query intents added to improve recall. Intent types matching Quantity, Weather, and Language (mostly dictionary lookups) are excluded.
Manual Hard Criteria: Each candidate question, generated from Automatic Hard Criteria, is manually labeled by multiple authors and candidate hard queries discussed by all authors. Guidelines include: non-factoid, beyond single passage, answerable, text-focused, mostly well-formed, and possibly complex.
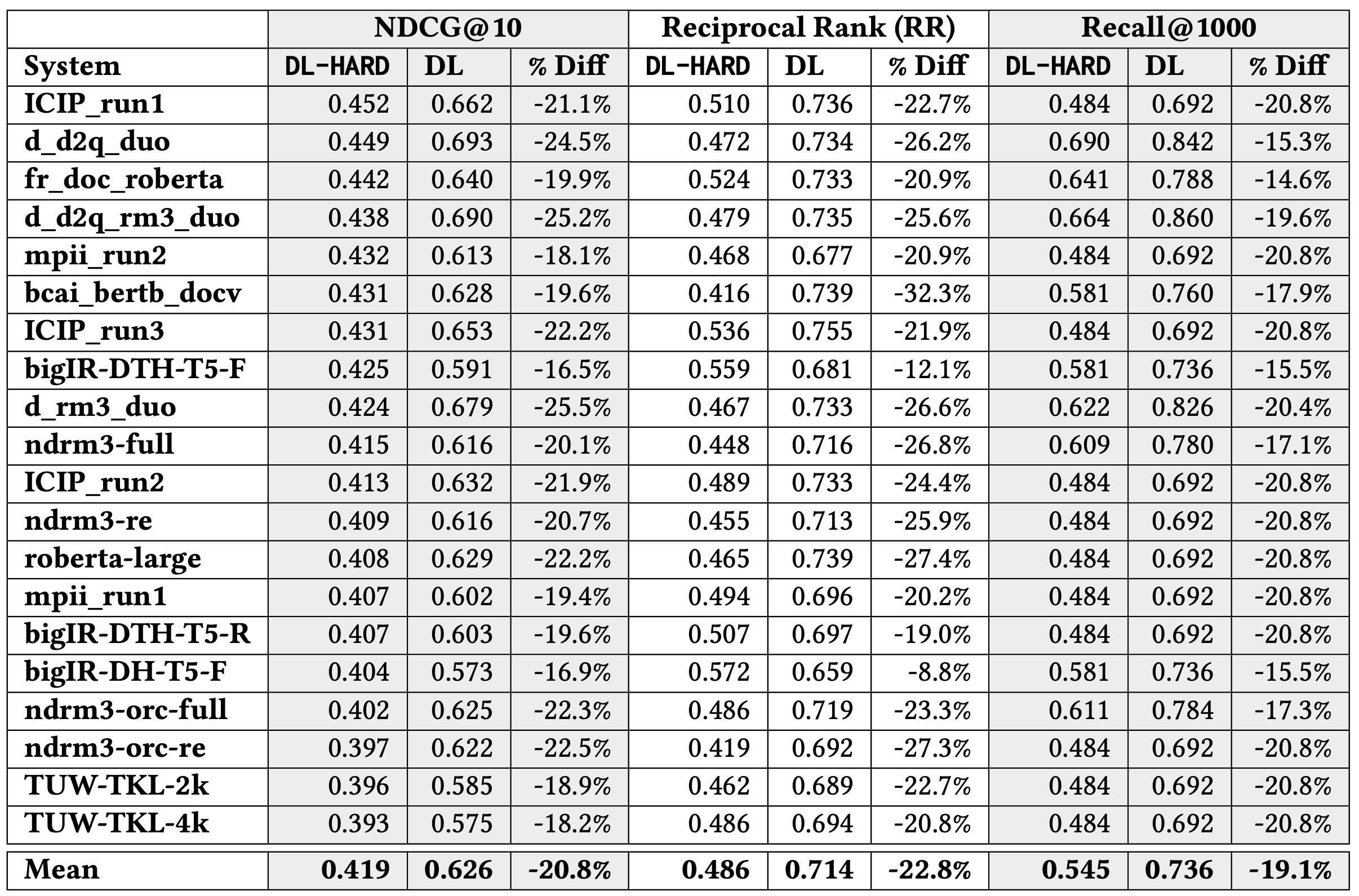
We measure official TREC 2020 document run submissions on DL-HARD overlapping subsets and compare to the original DL Track. On an average relative basis for above-median system, DL-HARD NDCG@10 is 21.1% lower, RR is 23.2% lower, and Recall@100 is 19.6% lower. This included a new top system (‘ICIP_run1’), and each system changed on average 4.6 places. This large number of swaps supports that removing the easier queries allows for a better comparison between state-of-the-art retrieval systems.
Top 20 systems’ effectiveness on DL-HARD compared with DL for the 2020 document ranking task:
Notebook Examples
We provide Pyserini (link) and PyTerrier (link) Colab Notebooks.
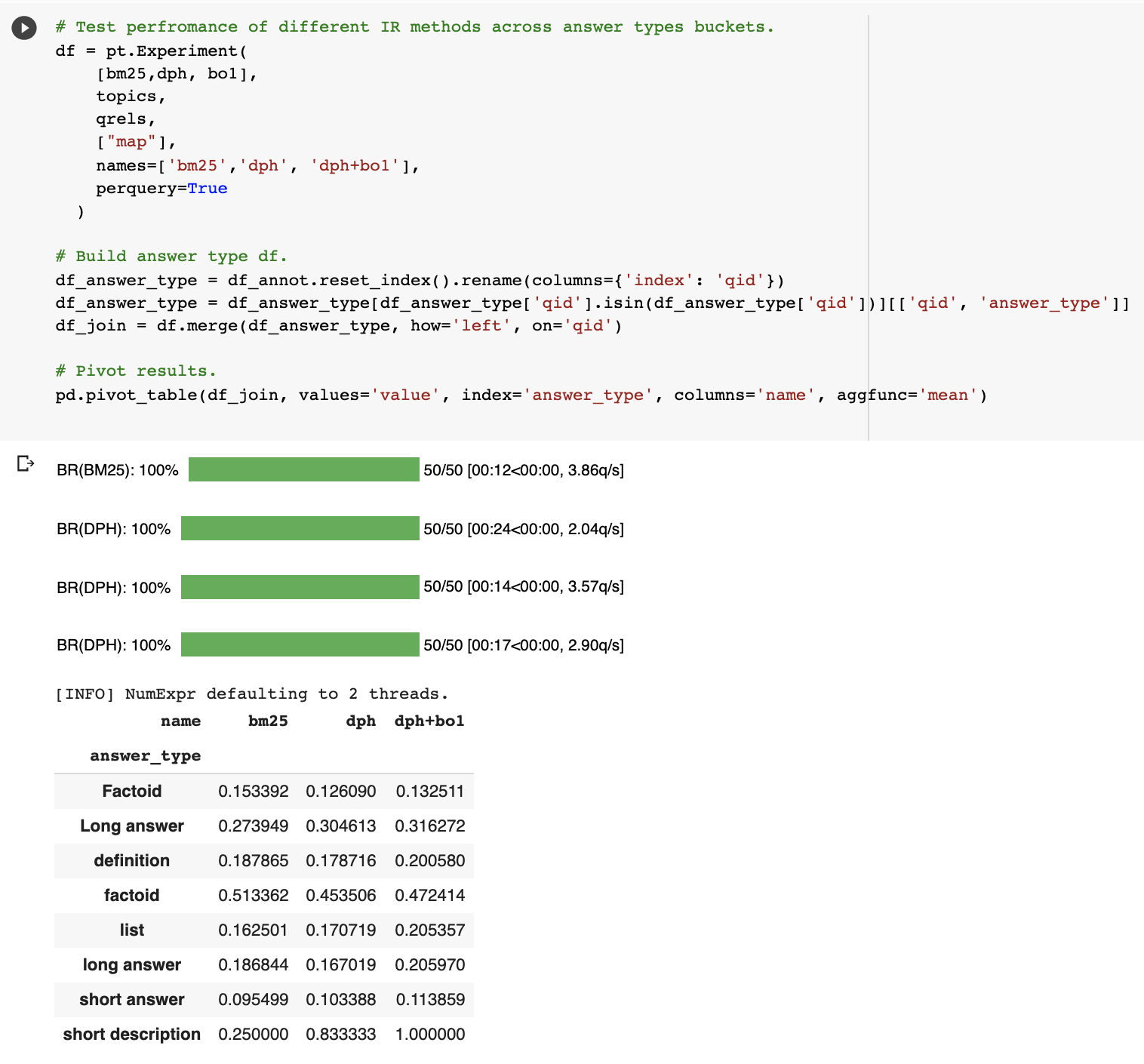
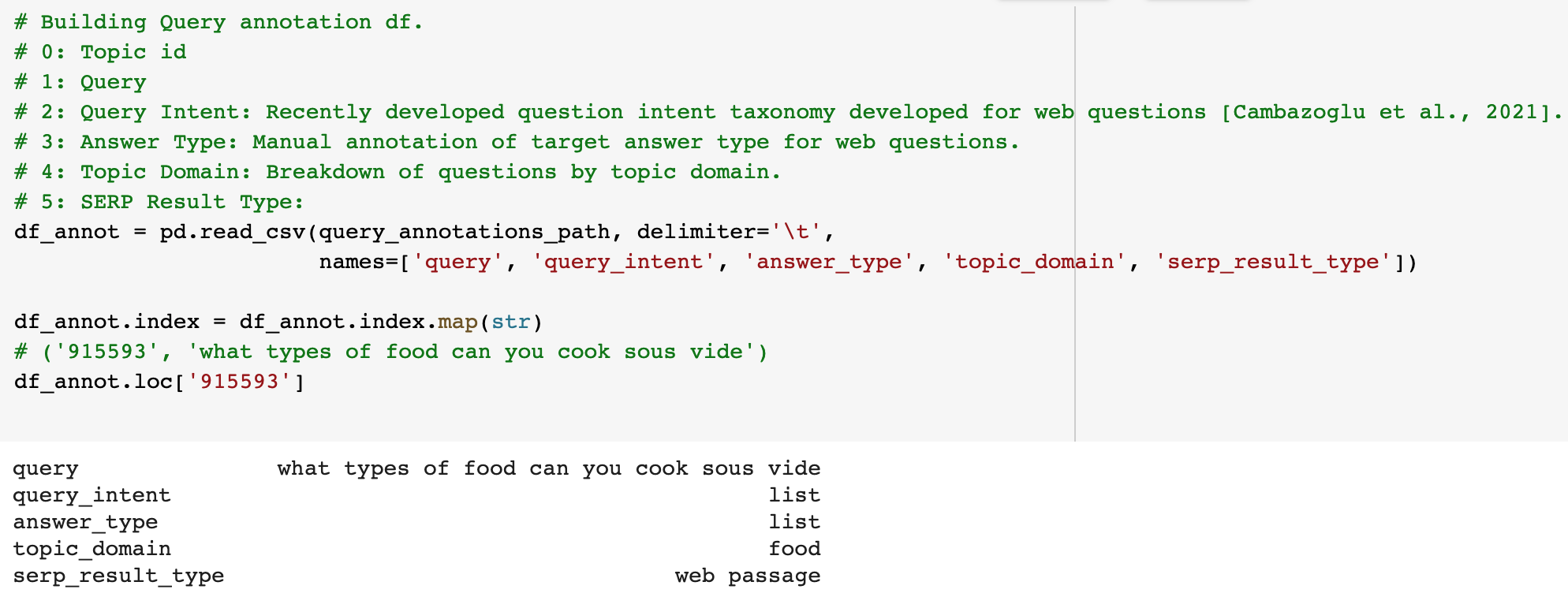
If we take a “hard” query (qid: 915593): what types of food can you cook sous vide. This query is classed as hard because it requires reasoning and the answer contains multiple entities spanning multiple documents.
Query annotations:
Entity Links:
The Answer Type of this query is a List. We can view Answer Type performance across DL-HARD early on PyTerrier baselines (passage ranking):